Use Case – Project Gateway

About Securities Industry Research Centre of Asia-Pacific (SIRCA)
SIRCA is an independent Australian company that provides online financial data and analytics services to academia.
SIRCA was founded in 1997 by a group of collaborating Australian and New Zealand universities as a not for profit company. SIRCA was created to support the needs of academic researchers, in a world where data volumes were accelerating dramatically.
The original group of founding universities has been joined by many more over the years; SIRCA now counts over 35 universities in Australia and New Zealand as Members, in addition to international universities, central banks, regulators and public sector agencies.
Thanks to the support of a number of commercial organizations, SIRCA provides its Members with access to vast and comprehensive online repositories of global news and financial markets data.
CMCRC-RoZetta
The CMCRC-RoZetta Group has been transforming research for over 20 years.
Formed through the merger of two Australian research powerhouses (the Capital Markets Cooperative Research Centre and RoZetta Technology), the Group’s world-leading technology and 350-strong network of experts delivers unrivalled capability in data engineering, mining, management, visualisation, AI/machine learning and analytics.
As a collaborative research institute and an AWS Advanced Consulting services business, the CMCRC-RoZetta Group partners with industry, government and academia to deliver commercial outcomes. To date, our work has delivered $1.8 billion in returns for our industry partners.
Our mission is making markets better for partners and customers through our services and solutions. These reduce fraud, waste, error and inefficiency in multiple global markets.
This lets our partners and customers:
- Solve major R&D challenges and other complex problems
- Permanently grow internal R&D capability
- Drive innovation and value creation
- Achieve business outcomes
- Unlock new business opportunities.
We are able to do this by:
- Embedding the best and brightest research minds with partner organisations through our Industrial PhD Program
- Providing access to purpose-built technologies
- Developing bespoke solutions
- Applying expertise in analytics, applied finance, artificial and augmented intelligence, big data and cloud-native application development on AWS
- Leveraging our Centres of Excellence in Finance, Energy, Health and Digital Finance Markets
- Investing in new technologies and creating new companies.
20+ years of technology innovation
The CMCRC-RoZetta group has a proud history of developing ground-breaking technology to improve market quality and provide benefit to the organisations and people who operate in those markets. This includes:
- SIRCA Gateway – cloud analytics platform enabling quality research
- Thomson Reuters Tick History – a multi-petabyte scalable platform to ingest, transform and present daily tick trades across 500+ global exchanges used by 650 global banks and hedge funds
- SMARTS Surveillance – the gold standard in market surveillance tech; identifies manipulation and insider trading; sold to Nasdaq in 2010
- Lorica Health – detects fraud, abuse, waste and errors in health market
- MQD – the world’s most sophisticated suite of data-research solution
- Cash – electronic cash
- Infinigold – lets investors buy, sell and hold physical gold in digital form.
The Challenge
SIRCA’s initial offering was to provide academics with research grade infrastructure. In 1997 when SIRCA was first created, it was not possible for an individual researcher to host and manage a large and diverse set of datasets such as ASX share market trade data and company announcements. At the time, SIRCA established physical infrastructure and built a custom portal application to provide easy access for researchers to the curated data.
Over time, the portal became difficult to maintain and the hardware and operating cost, prohibitive. At the same time, there was significant opportunity and demand to add and enrich the breadth of data provided to our subscribers. Given the expertise built in AWS native application development, it was obvious that any re-platforming should be on AWS offering a cloud based analytics environment leveraging spark in addition to the new datasets.
The goal was to build an analytics platform that would:
- Deliver maximum value in terms of data but at a competitive price
- Reduced maintenance costs
- Enable cloud based analysis on multi-terabyte datasets
- Enable the join of datasets based on user’s logic
- Enable users to execute queries using their preferred programming language
- Improve performance of queries
The Solution
RoZetta has built Gateway, a cloud-based analytics platform to help SIRCA provide its extensive new data collections to academics.
The platform has 5 major components:
- Data Capture
- Data Processing
- Data Ingestion into platform
- Analytics and visualization
- System Monitoring
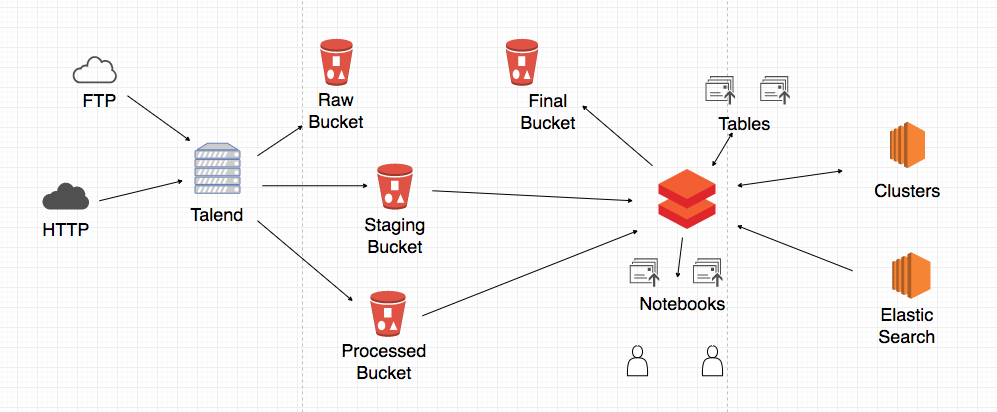
1. Capture
The Gateway Analytics Platform captures data from various sources. Most of its datasets are received via FTP, SFTP, FTPS or email. Our data providers Morningstar, ASX, Chi-X and Corelogic make their data available either daily or monthly.
Talend Data Management Platform
We have chosen the Talend Data Management Platform as our ETL tool to manage the capture and validation of the data from each of the sources.
The Talend data integration solution (which is part of the Data Management Platform) addresses both ETL for analytics and ETL for operational integration and is complemented with extended monitoring capabilities.
Talend has 2 major components: the TAC server and job severs. The Talend Administration Centre (TAC) server is comprised of an EC2 instance and an RDS database. The Talend Administration Centre centralizes the users’ role management and access rights to jobs and the scheduling and monitoring of processes (Jobs). Talend also has job servers which are EC2 instances that are used to execute the various jobs that are scheduled through the TAC.
Once the data is captured, this raw data is kept in S3 buckets.
2. Data processing
Once data is captured we execute a series of validation processes. Once these validations are successful the data will need to be processed. This step allows data to be prepared in a format that is ready for ingestion into the Gateway Analytics Platform. This processing may include data pivoting, data cleaning, merging a series of datasets to be presented as a single dataset, mapping certain fields to reference data fields.
This processing is scheduled to commence after the capture is completed and is handled by our ETL tool.
Once the processing is complete, the processed data is stored in S3 buckets.
3. Data ingestion
Once data is processed the data goes through a process of generation and preparation for ingestion. As data is prepped it will be placed on a staging S3 bucket.
This is mainly done as there are a number of embargo periods for each data set that SIRCA needs to comply to.
We also ingest data into an Elastic Search service for data that requires indexing for full-text search.
Once the data is ingested it will be kept on final S3 buckets ready to be used by the Gateway Analytics Platform.
4. Analytics and Visualization
Data is generally ingested into the platform once a month.
The Gateway Analytics Platform is powered by Databricks and this platform runs on AWS for provision of elastic cloud infrastructure.
The Databricks cluster runs on EC2 instances and the platform data is presented as tables. These tables generate metadata which is read from the S3 Final buckets where the data is ingested.
Databricks notebooks are one interface for interacting with Databricks. These notebooks allow users to write code so they can query the data. Notebooks support multiple programming languages such as Python, Scala, SQL and R.
5. System Monitoring
In addition to the monitoring provided by Talend for the scheduled capture, processing and ingestion jobs, a lambda service has been set up to monitor S3 buckets. The lambda service also monitors availability of the Databricks platform, Databricks Notebooks, Databricks tables, Elastic Search service. We also use a lambda service to monitor the load on the Gateway Analytics Platform.
The Benefits
The Gateway platform provides to academics the ability to access a number of data collections under the one platform. Users can also import their datasets and make use of the platform compute power without the need to set up expensive infrastructure. The performance obtained by leveraging spark clusters hosted on AWS means their queries can be executed within seconds. A fraction of the time it used to take using legacy techniques.
The platform also allows users to join datasets, explore and analyze the data with greater granularity and visualize their results with the charting tools available through Databricks.
With the use of the Gateway Analytics Platform users can improve team work and facilitate peer review with an integrated, multi user workspace. In addition, users can achieve transparency by sharing their notebooks and publishing their dashboards displaying their results from multiple studies.
In conclusion Rozetta has achieved the following for SIRCA:
- Creation of a highly scalable solution that is economic to operate where the operational cost can be adjusted based on subscription volume and platform usage.
- Ability to add more datasets into the platform without the need for lengthy manual processes or additional infrastructure to support the greater volumes of data
- An infrastructure that is simple to configure and maintain whilst maintaining high reliability and performance.
- Ability to support a variety of programming language options that allows users to query and analyze their data whilst enabling a collaborative workspace.
- A platform powered by Databricks that leverages native AWS technologies such as spot instances and auto scaling through an easy to use self-service administration console.
- A platform that leverages enterprise security and compliance with the use of integrated identity management, role based access controls and the ability to undertake secure deployments with minimal to zero downtime.
Technical Stack
- Python
- Pytest
- Pylint
- MySQL
- Databricks (Spark, Hive)
- Pager Duty
- Nightwatch
- BrowserStack
- Talend
- Splunk
- Git
- Jenkins
- Nexus
- Docker
- AWS S3
- AWS EC2
- AWS Lambda
- AWS Elasticsearch
- AWS RDS
- AWS IAM
- AWS CloudFormation
- AWS Email